This article shares some techniques and tools for building web apps using future friendly ES6 module syntax. We begin with an exploration of current module formats and ways to work both forwards and backwards in time.The complete code for this article can be found here.
For many years JS had a single widely accepted module format, which is to say, there was none. Everything was a global variable petulantly hanging off the window object. This invited risky propositions, too sweet to ignore, and some of us began monkey patching built in objects. Chaos prevailed. We had run amuck. The JS of that era was nightmarish, intertwined, lacking order and utterly without remorse.
Dark Ages
Long ago an adhoc group formed to solve the global conflict. The fruits of this vigilante justice are known today as CommonJS. Multiple competing formats were proposed and implemented in the wild by these dashing radicals and two bright lights emerged with significant adherents: AMD andCJS.
Asynchronous Module Design (AMD) accounts for the async nature of JS but some felt the aesthetics were harder to read with a wrapper function.
CommonJS (CJS) is synchronous, thus blocking, but generally understood to be an easier read.
Node famously chose CJS but the browser adherents flocked to AMD due to the nonblocking nature and dynamic friendly loading. Some view these technologies at odds, but together they prevailed and JS code became clear, easier to consume and compose. Chaos had been delayed by these twin forces of good.
Happening Right Now
At this point in time, Dec 2014, no module format actually matters if the developer is willing to pay for a build step that re-compiles the packages into a runtime source. We even retain debugging properties with sourcemaps. Dramatic scenarios staging CJS versus AMD end with the uninteresting conclusion being: “it depends on your project needs”.
Formal Standardization
While the primitive chaos of globals were being held back by the medieval outlaws of CJS and AMD a rational order of JavaScript vendors and concerned citizens began formally standardizing modules into the language proper.
JS is often called JavaScript but is more correctly referred to as ECMAScript (ES) as it is the ECMA-262 standard. After years of thrashing, a standard module format has finally emerged with ES version 6 (ES6).
Some people ❤ ES6 modules and some not-so-much. But as usual, neither camp actually matters: ES6 modules are happening and you can anticipate adoption. Great news: you can start now and compile to any module format of your choosing.
Setup
I’m going to author an ES6 module using package.json for manifest. We’ll use NodeJS and package manager npm to as our tool of choice for constructing the example.
This assumes you have Node installed and a BASH friendly shell. Open up your terminal and enter the following commands:
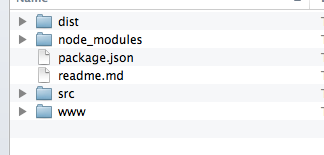
You end up with a very easy-to-reason-about package structure composed of plain directories and plain text files. No special editors or tools needed.
Authoring
Our next step is to write some code, and setup the 6to5 compiler. [Update:6to5 has been recently renamed to Babel.] Let’s start with a simple echoing function written in basic ES.
The shiny new ES syntax really surfaces the hidden beauty of JS. (I couldn’t be happier about this.)Like a butterfly it emerges from the cocoon of browser stagnation with poignant lucidity. If ES6 syntax freaks you out read this one pager. The quick explanation, we define a function called echo that accepts one parameter (called value), we return it concatenated with a string (thus casting it toString). We then export that function as the module default.
That’s it. (If you want a more complex example showing import’ing dependencies local and from npm have a look here.)
Compiling
Right now most JavaScript runtimes are still mostly ES5 based so we are going to compile our ES6 source code back to ES5 so it runs everywhere. In the future, we’ll be able to remove this step. Yay!
I set up the compilation in my package.json file as an npm script under the key compile. I’m using 6to5, for reasons I’ll describe more below, but keep in mind there’s many tools that do this. From my terminal I can now invokenpm run compile and it will produce valid ES5 code in my project ./distdirectory. The npm packager is super smart and will use the locally installed 6to5 in node_modules.
Many modules, 6to5 and Traceur included, encourage you to globally install them. This is a fragile practice as you might have multiple projects with dependencies on different versions of the same module. Rule of thumb: do not install Node packages globally if you can reasonably avoid it. You can almost always reasonably avoid it.
Testing in the Node runtime
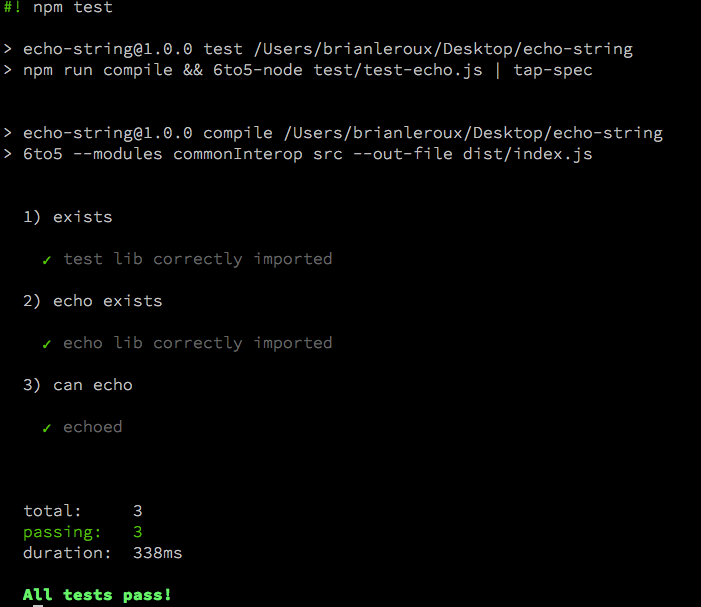
Test libraries come in many shapes and sizes. I happen to enjoy Tape but you may have found happiness elsewhere. That’s cool. You can view the whole source of this ES6 echo module on my Github. Clone the repo, run npm i to get the dependencies and finally npm test to check out the results.
For fun, I wrote the tests as ES6 JavaScript.
We import the tape modules and our own echo function using a relative path to package.json. The fat arrow => is just a shortcut for the word function. Otherwise this is the regular JS you are accustomed to. To run the tests, we issue the command: npm test. The script uses 6to5-node to automatically evaluate and execute the ES6 authored source. Note the ‘main’ key in package.json points to the compiled source in dist. Any modules including this module will use that path.
Testing in Browser runtimes
Let’s get this running in the browser. Before we test in a browser we’ll need to compile our source code for the browser runtime. This will be two steps: first we compile to ES5 and then we need to make the Node CJS module system browser compatible.
We’ll be using Browserify. Our build script gets updated to compile the tests to ES5, then compile the ES5 source for the browser. But we need a webpage to view this in! Here’s the one I added in test/index.html:
Note: we include the generated test-echo-browser.js script just below a div with the id=”out” (line 8). We’ll use that div to display the output of our tests.
To see those results we’ll npm i browserify-tape-spec —save-dev and import (line 3) the module and then use it at the bottom of our tests (line 21). If we’re running in the browser: pipe the results through our reporter and into that div.
This is low effort for a test rig. You can wire up Travis and Sauce Labs for maximal continuous integration should the module warrant it. We can add this stuff with time, there is no need to roll out the red carpet for an echo function.
Debugging
Sourcemaps to the rescue! Most compilers have an option for generating sourcemaps. Open the project in your dev tools of choice, you’ll see the futuristic flavored ES6 source, not the compiled ES5 source. Step debug will fully work.
Publishing
Code isn’t any fun if it only works on your machine. You need to ship it! Ship it real good. I hate myself for writing that.
Github
Most open source projects find themselves on Github. I add source code only and generally ensure compiled outputs are in my .gitignore.
The npm Registry
As with Git, we should only publish the bits relevant to the npm Registry. In this case we will ignore the source code and deliberately publish the compiled ES5 code. To do it we run: npm publish.
Publishing only ES5 source is not intuitive at first, but this way anyone targeting an ES5 runtime can use your ES6 authored module. (Which is everyone, for now.) Otherwise, we have to ask the module consumer to own the ES5 compilation. Chances are they already have a build step and chances are better they don’t want to add your build step to their pipeline.
Simply put, we can’t assume everyone will assume the same things. The only realistic assumption is the target runtime will be ES5 compatible.This will change when ES6 modules roll out but that will take time.
Browserify CDN
A magical side effect of publishing your module to npm is that it will also be available on http://wzrd.in/ which means you can include that module trivially. Browserify CDN exports your module using Browserify and lets you embed it anywhere.
Here’s an example with CodePen. You could embed in JSFiddle or JSBin or anywhere really and just start require-ing (or rather import-ing) your modules. Even better, RequireBin will automatically add scripts you require. Fun stuff.
Web
If we’re building things right then our applications are actually modules themselves. It is trivially easy to publish our web module using Github pages. A fun hack is to use git subtree to publish a compiled directory to your gh-pages branch. (But watch out, using subtree means you have to check generated files into your source control which is not ideal.)
Mobile
Any code that runs in a vanilla web browser ES5 runtime also runs in Cordova based projects like PhoneGap. Install the PhoneGap Developer App for iOS, Android, and Windows Phone and see for yourself. It is super easy to get started.
Discovery
Consuming modules from other people is fun. Most of the Node surface can be Browserified and most authors now ensure their Node modules are compatible with both Node and browser runtimes. You can search the registry for further browser ready modules and publish your own.
Issues
Of course this isn’t a perfect landscape. There are problems and the solutions have tradeoffs.
Default Key Emergence
In ES modules the keyword default denotes a default thing to export. Authors of Node style modules love to export only a single function. It is not the only way to do things but it is a very popular way. Unfortunately these concepts are not currently super compatible. Fortunately, 6to5 has a reasonable workaround which I anticipate will flow into the other transpilers. This gist demos the behavior:
The side effect emerges in the Node environment because default export is transpiled out to the object literal key default meaning if we are consuming a module in ES5 authored code we have to explicitly var foo = require(‘foo’).default …and most agree this doesn’t smell very nice. This also means other Node modules are harder to use and thus compose, disrupting the opportunity for reuse all the way down the stack.
Some solutions this default key emergence problem:
- Ignore ES modules until they land in all runtimes and continue to write ES5 CJS module.exports and require syntax (boo! hiss! boring!)
- Wholesale import * as foo from ‘foo’ and hope the foo package doesn’t change its exports (works, and is probably safe, but feels yolo)
- Pretend that appending .default is harmless aesthetics … ಠ_ಠ
- Brutally clobber the problem by appending module.exports = module.default at the end of each module in your ES5 publishing build pipeline (thunderbolt viking style! also yolo)
- Use the 6to5 compiler with the —modules commonInterop flag which does the expected thing: compile out a single function export to module.exports when there are no other named exports.
While we wait for an optimal native runtime env, workarounds are inbound for various compilers. Compiling to ES5 is what ultimately happens anyhow. I personally find 6to5 for publishing modules to npm the cleanest option, at the moment.
Small Modules
The UNIX philosophy lays down many interesting tenets. One of those tenets is do one thing and do it well. The idea manifests today as an avatar of small modules. Small modules compose better, are easier to reason about and test. It is now a classical concept but this timeless wisdom works well in any language and/or runtime.
Sometimes there is dissent to the idea of small modules with the primary claim being that authoring small modules is somehow at odds with using a framework. Supporters of the concept of small modules digest this baffling negativity and regurgitate with a narrative that frameworks themselves force unnecessary bloat. These concepts are not opposites but complementary; it is ridiculous nonsense to claim otherwise.
Frameworks are not at odds with modularity or discreet units of testable encapsulation, and indeed, all the “major” JS frameworks themselves are composed of small modules. Modules are a good idea.
Frameworks are not evil bastions of bloated lock in. Frameworks curate concepts to create a system symmetry that can enable developers with huge productivity boosts avoiding boilerplate. Frameworks are a good idea.
Frameworks and Small Modules currently coexist and are not mutually exclusive. Polarized debate about these ideas is a waste of time.
Other Minutia
But! AMD! Browserify supports exporting to AMD. There’s tonnes of tools for this and safely classifiable as a deployment concern.

But! Dynamic modules!
You can use any of these same tools to generate a standalone build and dynamically load it however you want.
However, I should warn you, if youdocument.write a script tag Steve Souders strangles this holiday deer with his bare hands.
Alternatives
I really like the output from 6to5. Google built Traceur, it works well, and is supported in CodePen which is fun. There’s a bunch of these things out there. (Which is great.) Choose whichever compiler path makes sense to you.
Just make sure:
- You are aware of the default key emergence problem in ES5 CJS runtimes
- You publish to npm as ES5 source so everyone can benefit from your hard work
There are numerous module-loader-compiler things too. Webpack, Spotify Quickstart and SystemJS are interesting alternatives to Browserify.
Summary
You can author, test, consume and deploy modules in the formats that make sense to you. I currently recommend publishing to npm as ES5 for maximal reuse. In this way, a project can then be authored in TypeScript, can consume CoffeeScript and JS modules, and deployed to the web as ES5 AMD. That code can be shared between browser, server and the phone in your pocket. Whatever makes sense for your project needs.
Think about that for a moment. Author in any language, use whatever transport makes sense and enjoy runtime agnostic code. This is the future of web development. That diversity is going to have wonderful side effects we can’t begin to anticipate and I personally find that strangeness very exciting and beautiful. Just like the web itself.