Lightweight virtualization", also called "OS-level virtualization", is
not new. On Linux it evolved from VServer to OpenVZ, and, more recently,
to Linux Containers (LXC). It is not Linux-specific; on FreeBSD it's
called "Jails", while on Solaris it’s "Zones". Some of those have been
available for a decade and are widely used to provide VPS (Virtual
Private Servers), cheaper alternatives to virtual machines or physical
servers. But containers have other purposes and are increasingly popular
as the core components of public and private Platform-as-a-Service
(PAAS), among others.
Just like a virtual machine, a Linux Container can run (almost)
anywhere. But containers have many advantages over VMs: they are
lightweight and easier to manage. After operating a large-scale PAAS for
a few years, dotCloud realized that with those advantages, containers
could become the perfect format for software delivery, since that is how
dotCloud delivers from their build system to their hosts. To make it
happen everywhere, dotCloud open-sourced Docker, the next generation of
the containers engine powering its PAAS. Docker has been extremely
successful so far, being adopted by many projects in various fields:
PAAS, of course, but also continuous integration, testing, and more.
Sunday, August 31, 2014
Saturday, August 30, 2014
Setting up a Multi-Node Mesos Cluster running Docker, HAProxy and Marathon with Ansible
The Google Omega Paper
has given birth to cloud vNext: cluster schedulers managing containers.
You can make a bunch of nodes appear as one big computer and deploy
anything to your own private cloud; just like Docker, but across any
number of nodes. Google’s Kubernetes, Flynn, Fleet and Apache Mesos,
originally from Twitter, are implementations of Omega with the goal of
abstracting away discrete nodes and optimizing compute resources. Each
implementation has its own tweak, but they all follow the same basic
setup: leaders, for coordination and scheduling; some service discovery
component; some underlying cluster tool (like Zookeeper); followers, for
processing.
In this post we’ll use Ansible to install a multi-node Mesos cluster using packages from Mesosphere. Mesos, as a cluster framework, allows you to run a variety of cluster-enabled software, including Spark, Storm and Hadoop. You can also run Jenkins, schedule tasks with Chronos, even run ElasticSearch and Cassandra without having to double to specific servers. We’ll also set up Marathon for running services with Deimos support for Docker containers.
Mesos, even with Marathon, doesn’t offer the holistic integration of some other tools, namely Kubernetes, but at this point it’s easier to set up on your own set of servers. Although young Mesos is one of the oldest projects of the group and allows more of a DIY approach on service composition.
Our masters run:
We want at least three servers in our master group for a proper zookeeper quorum. We use host variables to specify the zookeeper id for each node.
The mesos-ansible playbook will use nodes in the
Mesos-Slave will be configured with Deimos support.
We run four instances allocating 25% of a cpu with an application name of
To view marathon tasks, simply go to one of your master hosts on port 8080. Marathon will proxy to the correct master. To view mesos tasks, navigate to port 5050 and you’ll be redirected to the appropriate master. You can also inspect the STDOUT and STDERR of Mesos tasks.
There’s a high probability something won’t work. Check the logs, it took me a while to get things working: grepping
I didn’t cover inter-container communication (say, a website requiring a database) but you can use your service-discovery tool of choice to solve the problem. The Mesos-Master nodes provide good “anchor points” for known locations to look up stuff; you can always query the marathon api for service discovery. Ansible provides a way to automate the install and configuration of mesos-related tools across multiple nodes so you can have a serious mesos-based platform for testing or production use.
In this post we’ll use Ansible to install a multi-node Mesos cluster using packages from Mesosphere. Mesos, as a cluster framework, allows you to run a variety of cluster-enabled software, including Spark, Storm and Hadoop. You can also run Jenkins, schedule tasks with Chronos, even run ElasticSearch and Cassandra without having to double to specific servers. We’ll also set up Marathon for running services with Deimos support for Docker containers.
Mesos, even with Marathon, doesn’t offer the holistic integration of some other tools, namely Kubernetes, but at this point it’s easier to set up on your own set of servers. Although young Mesos is one of the oldest projects of the group and allows more of a DIY approach on service composition.
TL;DR
The playbook is on github, just follow the readme!. If you want to simply try out Mesos, Marathon, and Docker mesosphere has an excellent tutorial to get you started on a single node. This tutorial outlines the creation of a more complex multi-node setup.System Setup
The system is divided into two parts: a set of masters, which handle scheduling and task distribution, with a set of slaves providing compute power. Mesos uses Zookeeper for cluster coordination and leader election. A key component is service discovery: you don’t know which host or port will be assigned to a task, which makes, say, accessing a website running on a slave difficult. The Marathon API allows you to query task information, and we use this feature to configure HAProxy frontend/backend resources.Our masters run:
- Zookeeper
- Mesos-Master
- HAProxy
- Marathon
- Mesos-Slave
- Docker
- Deimos, the Mesos -> Docker bridge
Ansible
Ansible works by running a playbook, composed of roles, against a set of hosts, organized into groups. My Ansible-Mesos-Playbook on GitHub has an example hosts file with some EC2 instances listed. You should be able to replace these with your own EC2 instances running Ubuntu 14.04, our your own private instances running Ubuntu 14.04. Ansible allows us to pass node information around so we can configure multiple servers to properly set up our masters, zookeeper set, point slaves to masters, and configure Marathon for high availability.We want at least three servers in our master group for a proper zookeeper quorum. We use host variables to specify the zookeeper id for each node.
[mesos_masters] |
ec2-54-204-214-172.compute-1.amazonaws.com zoo_id=1 |
ec2-54-235-59-210.compute-1.amazonaws.com zoo_id=2 |
ec2-54-83-161-83.compute-1.amazonaws.com zoo_id=3 |
mesos_masters for a variety of configuration options. First, the /etc/zookeeper/conf/zoo.cfg will list all master nodes, with /etc/zookeeper/conf/myid being set appropriately. It will also set up upstart scripts in /etc/init/mesos-master.conf, /etc/init/mesos-slave.conf with default configuration files in /etc/defaults/mesos.conf.
Mesos 0.19 supports external executors, so we use Deimos to run docker
containers. This is only required on slaves, but the configuration
options are set in the shared /etc/defaults/mesos.conf file.Marathon and HAProxy
The playbook leverages anansible-marathon role to
install a custom build of marathon with Deimos support. If Mesos is the
OS for the data center, Marathon is the init system. Marathoin allows us
to http post new tasks, containing docker container
configurations, which will run on Mesos slaves. With HAProxy we can use
the masters as a load balancing proxy server routing traffic from known
hosts (the masters) to whatever node/port is running the marathon task.
HAProxy is configured via a cron job running a custom bash script.
The script queries the marathon API and will route to the appropriate
backend by matching a host header prefix to the marathon job name.Mesos Followers (Slaves)
The slaves are pretty straightforward. We don’t need any host variables, so we just list whatever slave nodes you’d like to configure:[mesos_slaves] |
ec2-54-91-78-105.compute-1.amazonaws.com |
ec2-54-82-227-223.compute-1.amazonaws.com |
The Result
With all this set up you can set up a wildcard domain name, say*.example.com,
to point to all of your master node ip addresses. If you launch a task
like “www” you can visit www.example.com and you’ll hit whatever server
is running your application. Let’s try launching a simple web server
which returns the docker container’s hostname:www. If we hit www.example.com,
we’ll get the hostname of the docker container running on whatever
slave node is hosting the task. Deimos will inspect whatever ports are EXPOSEd
in the docker container and assign a port for Mesos to use. Even though
the config script only works on port 80 you can easily reconfigure for
your own needs.To view marathon tasks, simply go to one of your master hosts on port 8080. Marathon will proxy to the correct master. To view mesos tasks, navigate to port 5050 and you’ll be redirected to the appropriate master. You can also inspect the STDOUT and STDERR of Mesos tasks.
Notes
In my testing I noticed, on rare occasion, the cluster didn’t have a leader or marathon wasn’t running. You can simply restart zookeeper, mesos, or marathon via ansible:/var/log/syslog will help, along with /var/log/upstart/mesos-master.conf, mesos-slave.conf and marathon.conf, along with the /var/log/mesos/.What’s Next
Cluster schedulers are an exciting tool for running production applications. It’s never been easier to build, package and deploy services on public, private clouds or bare metal servers. Mesos, with Marathon, offers a cool combination for running docker containers–and other mesos-based services–in production. This Twitter U video highlights how OpenTable uses Mesos for production. The HAProxy approach, albeit simple, offers a way to route traffic to the correct container. HAProxy will detect failures and reroute traffic accordingly.I didn’t cover inter-container communication (say, a website requiring a database) but you can use your service-discovery tool of choice to solve the problem. The Mesos-Master nodes provide good “anchor points” for known locations to look up stuff; you can always query the marathon api for service discovery. Ansible provides a way to automate the install and configuration of mesos-related tools across multiple nodes so you can have a serious mesos-based platform for testing or production use.
ANSIBLE IS THE BEST WAY TO MANAGE DOCKER

Docker is an exciting new open source technology that
promises to "help developers build and ship higher quality apps faster"
and sysadmins "to deploy and run any app on any infrastructure, quickly and reliably" (source: http://www.docker.com/whatisdocker/).
But to truly leverage the power of Docker, you need
an orchestration tool that can help you provision, deploy and manage
your servers with Docker running on them - and help you build
Docker-files themselves, in the simplest way possible.
ANSIBLE+DOCKER RESOURCES
Installing & Building Docker with Ansible - Michael DeHaan, CTO & Founder of Ansible
“To me
the interesting part is how to use Ansible to build docker-files, in the
simplest way possible. One of the things we've always preferred is to
have portable descriptions of automation, and to also get to something
more efficient to develop than bash.”
“By
using an ansible-playbook within a Docker File we can write our complex
automation in Ansible, rather than a hodgepodge of docker commands and
shell scripts.”
“One of
the more logical things to do is to use Docker to distribute your
containers, which can be done with the docker module in Ansible core.”
Read the full article here.
Docker Misconceptions - Matt Jaynes, Founder of DevOpsU
"...you
absolutely need an orchestration tool in order to provision, deploy, and
manage your servers with Docker running on them.
This is
where a tool like Ansible really shines. Ansible is primarily an
orchestration tool that also happens to be able to do configuration
management. That means you can use Ansible for all the necessary steps
to provision your host servers, deploy and manage Docker containers, and
manage the networking, etc."
"So, if
you decide you want to use Docker in production, the prerequisite is to
learn a tool like Ansible. There are many other orchestration tools
(some even specifically for Docker), but none of them come close to
Ansible's simplicity, low learning curve, and power."
Read the full article here.
The Why & How of Ansible & Docker - Gerhard Lazu, a contributor to The Changelog
"Ansible
made me re-discover the joy of managing infrastructures. Docker gives
me confidence and stability when dealing with the most important step of
application development, the delivery phase. In combination, they are
unmatched."
Read the full article here.
VIDEO: Ansible + Docker Demonstration - Patrick Galbraith, HP Advanced Technologies
Friday, August 29, 2014
New iPhone 6 leaking picture
 It’s happening. Apple’s invitation to a September 9 event has officially gone out. At least one next-gen iPhone will be unveiled in a few short days. However, new photos have emerged on Chinese site WeiFeng that appear to show components that match up almost identically to previous leaks for a 4.7-inch iPhone.
It’s happening. Apple’s invitation to a September 9 event has officially gone out. At least one next-gen iPhone will be unveiled in a few short days. However, new photos have emerged on Chinese site WeiFeng that appear to show components that match up almost identically to previous leaks for a 4.7-inch iPhone. If these numerous leaks are to be trusted as the real deal, and we are, in fact, looking at parts for the next iPhone, then you’ll notice that this design language is quite a departure from the past few generations of the iPhone. From the iPhone 4 onward (with the slight exception of the iPhone 5c), the iPhone has had a flat face and back, with rounded corners.
These components point to a more iPad mini-like shape, with four strips of plastic seemingly running across the back of the device. As AppleInsider mentions, the strips in these most recent photos seem to be closer to the color of the metal back of the phone, as opposed to previous leaks. This might suggest that we’re seeing a more finalized version.
However, we’ve also heard rumors that claim that the plastic strips are just a preliminary design, and will eventually be replaced by glass, which would look a bit closer to the current iPhone 5s.
All that said, with a bigger screen and a more durable design, this next iPhone could be the device of the year.
Thursday, August 28, 2014
Microsoft Azure Now Supports Google’s Kubernetes For Managing Docker Containers
Back in June, Microsoft announced that it would bring support for managing Docker containers with the help of Google’s open-source Kubernetes tool to Azure and today, it is making good on this promise. Most of the work on this integration was done by Microsoft Open Technologies, the company’s subsidiary for working on open-source technologies and interfacing with the open-source community.
What’s cool about Microsoft’s implementation of Kubernetes is that the Azure team also built a dashboard for visualizing your Kubernetes setup on its platform. Microsoft says the imaginatively named Azure Kubernetes Visualizer project will make it “much easier to experiment with and learn Kubernetes on Azure.” The Visualizer, it turns out, is actually one of the results of Microsoft’s first company-wide hackathon last month.
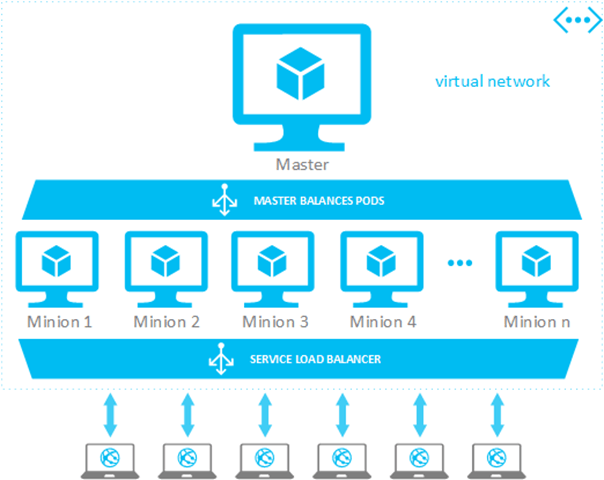
With Docker and Kubernetes on Azure, developers will be able to build
their containers and publish them on Azure’s storage service, deploy
Azure clusters using those container images stored on Azure or those
hosted on the main Docker Hub, and configure, update and delete their clusters.
All of this means you can now use the same tools to manage your Docker containers on Azure and Google Compute Engine, for example. That’s an odd paring and we don’t usually expect to read about it in Microsoft press releases. Docker — and the concept of containers in general — is quickly becoming so popular, however, that everybody is now trying to embrace it as fast as possible. That even includes the likes of VMware, for which Docker is actually a real threat.
What’s cool about Microsoft’s implementation of Kubernetes is that the Azure team also built a dashboard for visualizing your Kubernetes setup on its platform. Microsoft says the imaginatively named Azure Kubernetes Visualizer project will make it “much easier to experiment with and learn Kubernetes on Azure.” The Visualizer, it turns out, is actually one of the results of Microsoft’s first company-wide hackathon last month.
All of this means you can now use the same tools to manage your Docker containers on Azure and Google Compute Engine, for example. That’s an odd paring and we don’t usually expect to read about it in Microsoft press releases. Docker — and the concept of containers in general — is quickly becoming so popular, however, that everybody is now trying to embrace it as fast as possible. That even includes the likes of VMware, for which Docker is actually a real threat.
Wednesday, August 27, 2014
Is Ghost Really a WordPress Killer?
In the case of WordPress, what started out as a clean framework for publishing to the web has now grown into a fullfledged CMS aimed at tackling entire websites. So what about those folks that still desire a simple and effective way to write to the web without the overhead of a feature rich CMS? Well, as of a few short weeks ago (October 14th to be precise) there’s a new entry in the blogging platform race that hopes to meet your less demanding needs.
A focus on writing
This new entrant goes by the stealthy moniker Ghost. A fitting name really, given its unapologetic focus on nofrills web publishing. The pet project of former WordPress UI team member John O’Nolan, Ghost was created out of frustrations with current blog builders. Ghost’s own “About” page says it best when discussing John’s motivations:“After years of frustration building blogs with existing solutions, he wrote a concept for a fictional platform that would be once more about online publishing rather than building complex websites.”
Forgoing the now ubiquitous use of nested menus with complex site tools, Ghost gives bloggers a spartan array of options. The everpresent main menu contains only four choices: view blog, browse posts, create a new post, and blog settings. Yep, that’s it. Kind of refreshing really.
Elegant editing
Clicking on the “Content” option brings up a list of all posts both published and otherwise.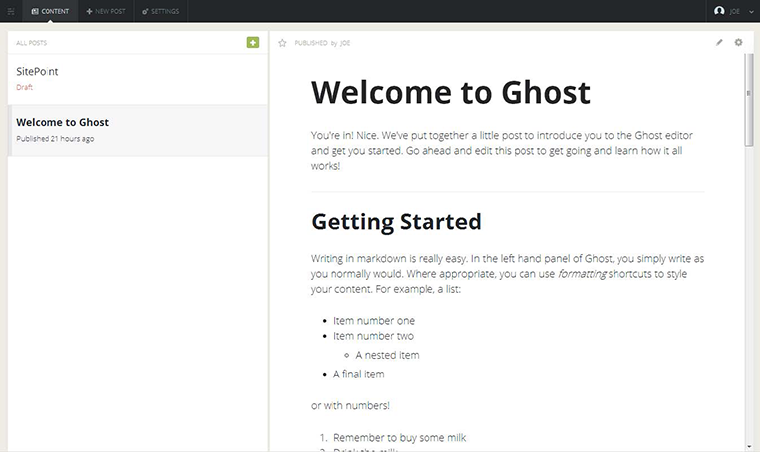
Simply click the edit icon on any given post and you’re whisked away to an elegantly sparse editing view. Inside this view is a double pane window with markup on the left and a live, realtime preview on the right.
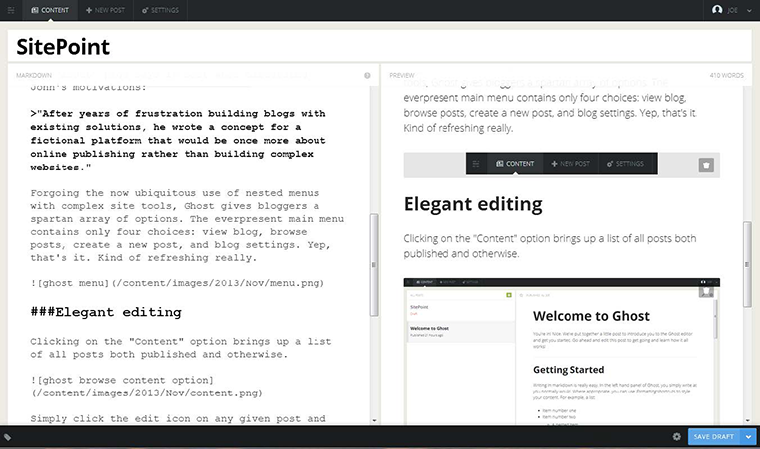
Markup and HTML can be typed into the left pane and the right pane automatically updates with the converted content in realtime. This works marvelously well and lets you, as the blogger, focus on producing quality content without the distraction of jumping through menus and page previews.
The real usefulness of Ghost’s editing approach lies in the flexibility of the markup language. With the double pane feature you’ve essentially got the power and portability of markup with the aesthetics of a WYSIWYG editor. It’s the best of both worlds.
As a quick example of the seamless (and productive) combination of the two pane method; to insert an image you would simply create the markdown alt text ![alt image text] as a sort of “placeholder” and then drag and drop the desired image into the designated area. The image is automatically uploaded and placed in the post. Both easy and efficient.
Simple doesn’t mean shallow
Despite Ghost’s simplistic approach to blogging it retains a surprising penchant for extensibility. The ghost team has set out from the getgo to provide excellent plugin support via official API’s along with easy methods of distribution through their own “Marketplace“.Within the marketplace users will be able to browse and download both paid and free Ghost extensions. In its current form, the Ghost marketplace showcases only themes with plugins coming later on down the road. Also on the way is the highly touted Ghost dashboard which will pull in and present useful analytics. The dashboard will be easily customized with drag and drop widgets to represent the desired data.
Here’s the official mockup:
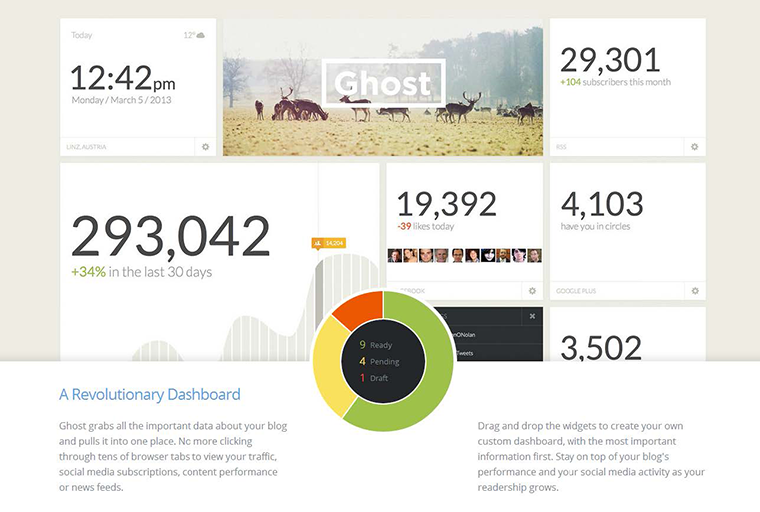
Under the hood
For the dev types among you, Ghost has been developed as a node app written in JS. This leads to a slightly more complicated installation than its WordPress counterpart, though much of the setup can now be accomplished through automatic installers provided by third parties.By default, Ghost utilizes SQLite3 as the chosen database for storing content though you’re free to choose your own backend by editing the config.js file in the Ghost install directory.
Here’s an example using MySQL as the database:
1
2
3
4
5
6
7
| database: { client: 'mysql', connection: {host: 'localhost', user: 'ghostUser',password: 'ghostPass', database: 'ghostDB', charset: 'utf8'}} |
Ghost’s own hosted service is set to debut in the near future. Those that subscribe to the service will reportedly get the “full experience”. According to the Ghost website itself:
“You’ll need hosting for your blog no matter what, but our service will be the most powerful way of running Ghost and the easiest to get started with. You’ll have the full Ghost software with all bells, whistles, themes, plugins, and some extras that are only available with us (like automatic updates and backups).”
The end of WordPress?
A silly question really, as the two platforms aren’t at odds as much as you might think. As stated briefly above, WordPress sets out to accomplish far more and has a much wider use case.Ghost on the other hand is created to be a simple platform for writing to the web. Nothing more, nothing less.
That being said, the release of Ghost holds great promise for the future of blogging and gives current bloggers ample reason to take a hard look at their own platforms and decide if maybe they could do without all the excess. Should you decide to jump ship or even just test the waters, there’s already an official WordPress plugin capable of migrating your WP posts over to Ghost’s open arms.
Ghost is an open source project, free of charge and can be downloaded from the Ghost website immediately.
Solr vs ElasticSearch
Background
The first thing you should know about Solr and
ElasticSearch is that they are competing search servers. Both
ElasticSearch and Solr are built on top of Lucene, so many of their core
features are identical. If you are unfamiliar, Lucene is a search
engine packaged together in a set of jar files. Many custom applications
embed the Lucene jar files directly into their application and manually
create and search their Lucene index through the Lucene APIs.
Solr and ES take those Lucene APIs, add features on top of
them, and make the APIs accessible through an easy to deploy web server
(like tomcat or jetty). Instead of coding through the Lucene Java API,
developers can now easily shoot http commands to the search server and
index/search that way.
Distributed Search
Foundations
Solr was released in 2008. The Solr commiters focused on
building new search features. Later, it became obvious that distributed
search was a highly desired feature. In October of 2012 Solr released
the SolrCloud feature set which was supposed to make distributed search
easy. People like to say that Solr brought distributed search on as an
afterthought. On the other hand, ElasticSearch was released in 2010
specifically designed to make up for the lacking distributed features of
Solr. For this reason, you may find it easier and more intuitive to
start up an ElasticSearch cluster rather than a SolrCloud cluster
Winner: ElasticSearch
Coordination
ElasticSearch uses its own internal coordination mechanism
to handle cluster state while Solr uses ZooKeeper. This means in order
to have a SolrCloud, you have to have a ZooKeeper quorum setup. For a
lot of folks using different components in the Hadoop ecosystem, this
isn’t a problem since they will most likely already have a ZooKeeper
quorum started up. In addition, by using ZooKeeper Solr can avoid a
split brain scenario that ElasticSearch is vulnerable to. I’ll mark this
section as a toss up.
Winner: Toss Up
Shard Splitting
Shards are the partitioning unit for the Lucene index, both
Solr and ElasticSearch have them. You can distribute your index by
placing shards on different machines in a cluster. Until April 2013,
both Solr and ElasticSearch would not allow you to change the number of
shards in your index. So if you decided you wanted to split your index
into 10 shards on day one, and two years later you want to add another 5
shards, you were not able to do that without completely starting over
(reindexing everything). As of April 2013 Solr supports shard splitting, which allows you to create more shards by splitting existing shards. ElasticSearch still does not support this.
Winner: Solr
Automatic Shard Rebalancing
Let’s say you’re in charge of capacity planning for your
ElasticSearch index. Today, you have 5 machines, but you know in the
future you will have budget for 20 machines by the end of this year. To
make best use of those 20 machines next year, you decide that it would
make most sense to split your index into 10 shards, and have 1 replica
of each shard (10 shards and 10 replica shards = 20 total shards). Then
you would have either 1 shard or 1 replica shard on each machine in your
cluster. Since you only have 5 machines today, multiple shards will
have to shard the same machine. As you add new machines, ElasticSearch
will automatically load balance and move shards to new nodes in the
cluster. This automatic shard rebalancing behavior does not exist in
Solr.
Winner: ElasticSearch
Schema
Schema-less?
To be 100% clear, both Solr and ElasticSearch provide
dynamic typing so that you can index new fields on the fly (after you
have already defined your schema).
Winner: Users
Schema Creation
ElasticSearch will automagically create your schema based
on the data you are indexing. Solr on the other hand requires you to
define a schema before you index anything. In production for either Solr
or ElasticSearch, you’ll want to define your schema before you index
anything. This is because there are many advanced analyzers/filters you
will want to apply on the data before you index it.
Winner: Both
Nested Typing
ElasticSearch supports complex nested types. For example,
you could have an address field that contains a home field and a work
field. Each of those fields would have street, city, state, and zip
fields. These nested types only work for 1 (parent) to many (child)
relationships. There are also a lot of “gotchyas” here. For example,
with parent-fields, all members of a relationship must fit onto one
shard in your index. Or for nested fields, updating may be extremely
slow if you make any updates to any field in the nest. Solr does not
support nested typing, the document structure must be flat. The fact
that these options exist in ElasticSearch is very cool, but you have to
be very careful with how you use them.
http://www.elasticsearch.org/guide/reference/mapping/nested-type/http://www.elasticsearch.org/guide/reference/mapping/object-type/http://www.elasticsearch.org/guide/reference/mapping/parent-field/
Winner: ElasticSearch
Queries
Query Syntax
Solr’s query syntax is key/value pair based using / and () to delineate and nest queries. For example
q=((name:ryan* AND haircolor:brown) OR interest:zombies) OR (job: engineer*).
ElasticSearch’s uses JSON. For example here is an ElasticSearch query:“bool” : {
“must” : {
“term” : { “user” : “kimchy” }
},
“must_not” : {
“range” : {
“age” : { “from” : 10, “to” : 20 }
}
},
“should” : [
{
"term" : { "tag" : "wow" }
},
{
"term" : { "tag" : "elasticsearch" }
}
],
“minimum_should_match” : 1,
}
}
Winner: Users
Distributed Group By
Solr supports distributed group by (including grouped
sorting, filtering, faceting, etc), ElasticSearch does not. This feature
seems to be like a no brainer in most any search applications which is
why I call it out specifically here.
Winner: Solr
Percolation Queries
ElasticSearch allows you to register certain queries that
can generate notifications when indexed documents match that query. This
is really great for things like alerts. This may cause performance
issues if you have too many percolated queries as each document that is
indexed will be queried by each percolated query. If the newly indexed
document is returned by one of the percolated queries then an alert is
sent out.
Winner: ElasticSearch
Community
Users
ElasticSearch is still fairly new but its community is
growing very quickly. Solr has been around for much longer and therefore
has a larger user base.
Winner: Solr
Vendor Support
MapR, Cloudera, and DataStax have all chosen Solr for their
search technology. InfoChimps is using ElasticSearch. I haven’t heard
any word on if HortonWorks is even looking into search at this point.
LucidWorks has many of the Solr committers and provides an enterprise
Solr product with more features, while ElasticSearch provides most of
the support for their product. Think Big also supports Solr and
ElasticSearch, especially when it comes to integrating these
technologies with big data. I see DataStax and Cloudera as thought
leaders in this area, which is why I give the win to Solr.
Winner: Solr
Conclusion
So ElasticSearch received four winner categories and Solr
received four. Regardless of how to counts were going to end up, I never
wanted to say that ElasticSearch is better than Solr or Solr is better
than ElasticSearch. At the end of the day Solr and ElasticSearch are
very close to each other in feature sets, and it would be really
difficult to make a decision on one or the other without really knowing
the exact requirements your organization has.
Origin post: https://thinkbiganalytics.com/solr-vs-elastic-search/
Subscribe to:
Comments (Atom)